· Brittany Ellich · notes · 6 min read
Incident investigation
Overview
When things break—whether it’s a service outage or a degradation in performance—the pressure to fix the problem can feel immense. But once the smoke clears, the real value comes from what happens next: the investigation.
Incident investigation isn’t just about fixing the immediate issue. It’s about understanding why the issue occurred, how it was managed, and identifying what can be done to prevent it from happening again. This practice, when done properly, helps transform a single incident into an opportunity for improvement.
In this issue, we’re going to explore the best ways to investigate availability incidents, including how frameworks like the Heinrich Safety Pyramid, a concept from my previous career in Occupational Health and Safety, can be applied to software incidents.
Step 1: What is an Incident Investigation?
An incident investigation is a structured process aimed at understanding the root causes of an availability problem. It’s about answering the key questions:
- What happened?
- Why did it happen?
- How did we respond?
- What can we do to prevent this from happening again?
The goal is to move beyond the immediate response and work towards a comprehensive understanding of the factors at play. This means looking at technical, process, and human factors. Investigations can take different shapes depending on the nature of the incident, but at the core, they should be fact-based, thorough, and focused on learning.
Step 2: The Anatomy of a Good Postmortem
Postmortems or incident reviews are a vital part of any investigation. A solid postmortem doesn’t just list the timeline of events—it digs deeper. Here are the main elements you should include:
Incident Timeline
A clear, chronological account of what happened, from detection to resolution. This should include timestamps, who was involved, and the decisions made.Impact Assessment
Understanding the scale of the incident is crucial. How many users were affected? Was it a full outage or a degradation? This will inform your response strategy and help prioritize follow-ups.Root Cause Analysis
The key to preventing future incidents. Use tools like the Five Whys or Fishbone Diagram to ask why the issue occurred at each layer of your systems (infrastructure, application, dependencies, human error, etc.).Response and Mitigation
Analyze how the team responded during the incident. Were there clear communication channels? Did the team have the necessary tools and knowledge? This helps identify gaps in processes and training.Preventive Measures and Action Items
This is where the future-proofing happens. What changes can be made to systems, processes, or tools to prevent recurrence? Include actionable items with owners and deadlines.
By following this framework, you move the postmortem from a mere fact-finding mission to a valuable tool for continuous improvement.
Step 3: The Heinrich Safety Pyramid and Software Incidents
Let’s talk about a concept that’s often used in safety-critical industries like aviation, healthcare, and manufacturing: the Heinrich Safety Pyramid.
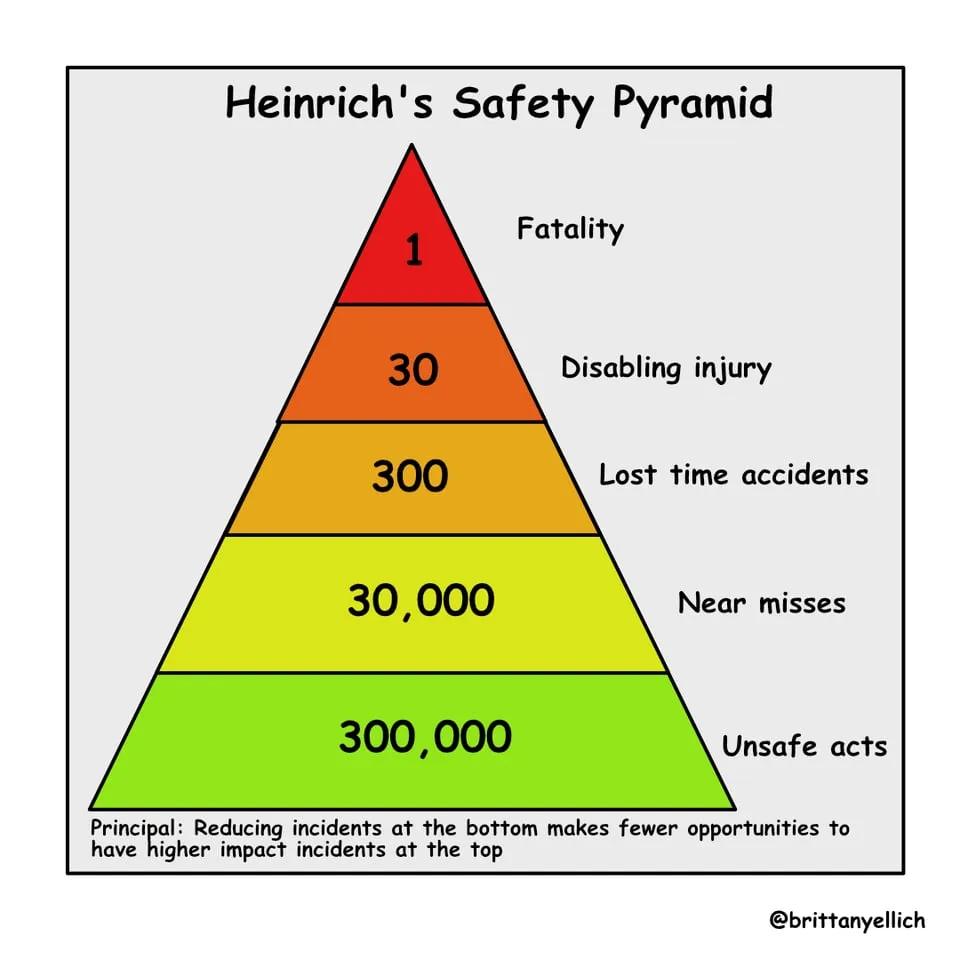
The pyramid is a model that helps organizations understand the relationship between different types of incidents. It’s based on the idea that for every major accident (the tip of the pyramid), there are many smaller, less significant incidents (the base).
A healthy safety organization will put just as much focus on items at the bottom of the pyramid as at the top, and will do incident investigations for all of them. By making the bottom of the pyramid of the smaller, they will also make the top of the pyramid smaller, reducing the likelihood of serious accidents.
The Heinrich Safety Pyramid in the context of software engineering suggests that if you’re only investigating major incidents, you’re missing a huge portion of your risk landscape. While big incidents grab attention, the small issues—often seen as “minor” or even “inconsequential” by the team—can be the indicators of systemic weaknesses that will eventually lead to something catastrophic.
I propose that we apply the Heinrich Safety Pyramid to software incidents, too:
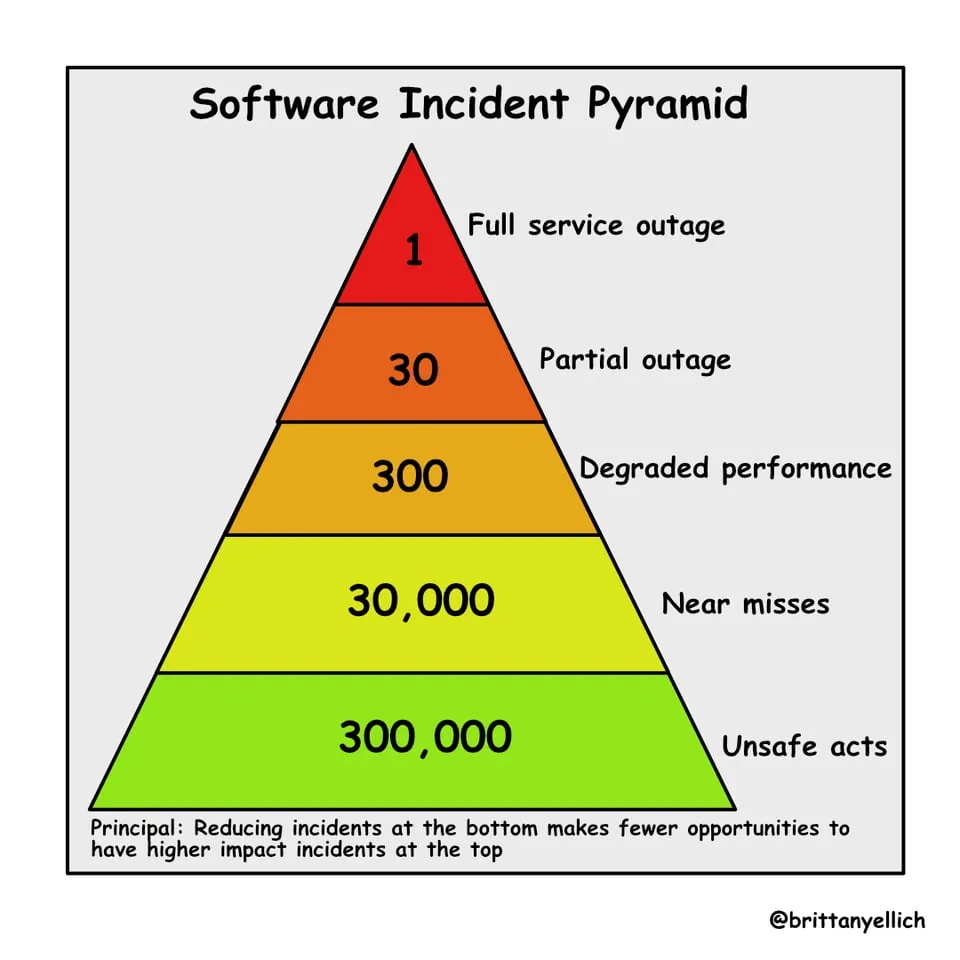
This means your team should not just focus on investigating major outages. You should also consider the smaller incidents and almost-incidents that happen frequently.
How does this apply to incident investigations?
- High-severity incidents (the top of the pyramid) should get a thorough postmortem, of course. But don’t stop there. You should also be looking at minor incidents (middle of the pyramid) and understanding whether there’s a common theme or underlying problem.
- The frequent, low-severity events (bottom of the pyramid) might seem like nothing to worry about individually, but when viewed together, they often point to something more significant that needs addressing before it causes a larger failure.
By adopting a broader, more holistic view of incidents, engineers can find patterns in the system’s behavior that may not be obvious in the heat of the moment but could indicate future risks.
Step 4: Blurring the Lines Between Human and Systemic Factors
One of the key insights from applying the Heinrich Safety Pyramid to software is the importance of understanding human factors in incidents. In safety-critical industries, it’s common to blame human error when something goes wrong. But as we all know, human error is often a symptom of a deeper issue—like bad design or inadequate tooling. In the same way, when a software incident happens, it’s not just about blaming the developer who introduced the bug, but asking: What in our process, culture, or tooling led to this mistake?
For example, during an investigation, you might uncover that a piece of critical infrastructure was too complex or lacked the necessary documentation. It’s not just a single engineer’s fault—it’s a systemic issue.
Pro tip: When conducting an investigation, it’s useful to consider the “Swiss Cheese Model” of accident causation. This model suggests that accidents occur when multiple layers of defense fail, like slices of Swiss cheese with holes in them. When everything aligns, you get a perfect storm that leads to a major failure. The goal is to reduce those holes at every layer: the code, the process, the monitoring, and so on.
Step 5: Learning from Each Incident
Investigating incidents isn’t just about finding the cause—it’s about learning from it. The ultimate goal is to create a feedback loop that improves your systems, processes, and team culture over time.
A well-conducted incident investigation should result in:
- More robust systems that can handle future incidents more gracefully
- A culture of continuous learning, where every incident becomes an opportunity to improve
- Better communication and collaboration across teams, especially during high-stress situations
Remember, availability incidents are inevitable. What matters is how you respond, learn from them, and build a more resilient system for the future.